Yun Zhang

I am currently a first-year PhD student at the the UCLA’s Mobility Lab, working under the guidance of Prof. Jiaqi Ma and Prof. Wei Wang. My research focuses on vision-language-action (VLA) systems and embodied intelligence, with an emphasis on enabling agents to perceive, reason, and act effectively in real-world environments.
My work lies at the intersection of robotics, artificial intelligence, and mobility. I am particularly interested in developing methods that allow physical AI systems to integrate visual and linguistic understanding with action, maintain structured memory over time, and perform reliable decision-making in long-horizon tasks. My research spans topics including navigation, manipulation, and memory-driven reasoning, with the goal of building robust and adaptable embodied agents.
I am also an Amazon Trainium Fellow, supported for my research on large-scale vision and action learning for embodied intelligence.
news
| Oct 19, 2025 | Thrilled to announce that our paper MIC-BEV: Multi-Infrastructure Camera Bird’s-Eye-View Transformer with Relation-Aware Fusion for 3D Object Detection received the Best Paper Award (Third Prize) at the ICCV 2025 DriveX Workshop. |
|---|---|
| Aug 19, 2025 | Honored to be selected as a 2025 Amazon Trainium Fellow. |
| Apr 07, 2025 | I’m excited to share that I’ve been selected as a recipient of the 2025 RSS Pathway Fellowship Program! Grateful to RSS for this opportunity to connect with the robotics community and further explore my research interests. |
| Mar 17, 2025 | Thrilled to share that I’ve been selected to receive the prestigious Graduate Dean’s Scholar Award (GDSA) from UCLA’s Division of Graduate Education, enhancing my student financial support with awards totaling $14,500 over the next two years. |
| Jan 09, 2025 | Excited to won the U.S. Department of Transportation’s Intersection Safety Challenge as core developer. Recieving $750,000 cash prize. |
selected publications
-
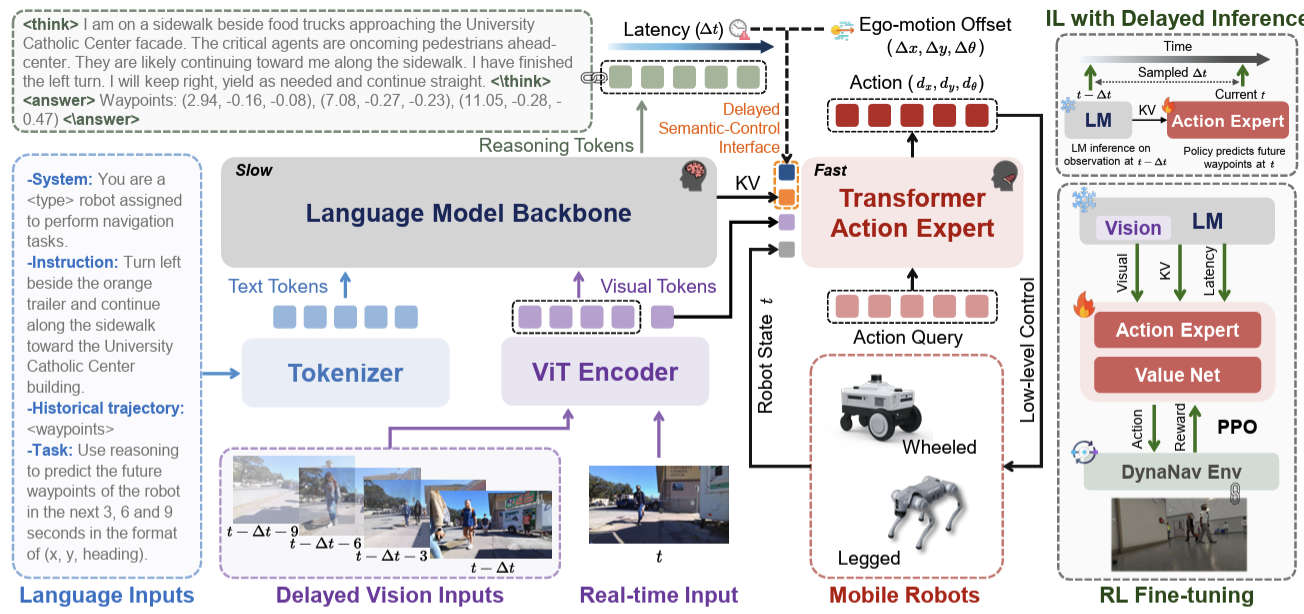 TIC-VLA: A Think-in-Control Vision-Language-Action Model for Robot Navigation in Dynamic EnvironmentsInternational Conference on Machine Learning (ICML), 2026Zhiyu Huang*, Yun Zhang*, Johnson Liu, Rui Song, Chen Tang, and Jiaqi Ma
TIC-VLA: A Think-in-Control Vision-Language-Action Model for Robot Navigation in Dynamic EnvironmentsInternational Conference on Machine Learning (ICML), 2026Zhiyu Huang*, Yun Zhang*, Johnson Liu, Rui Song, Chen Tang, and Jiaqi Ma -
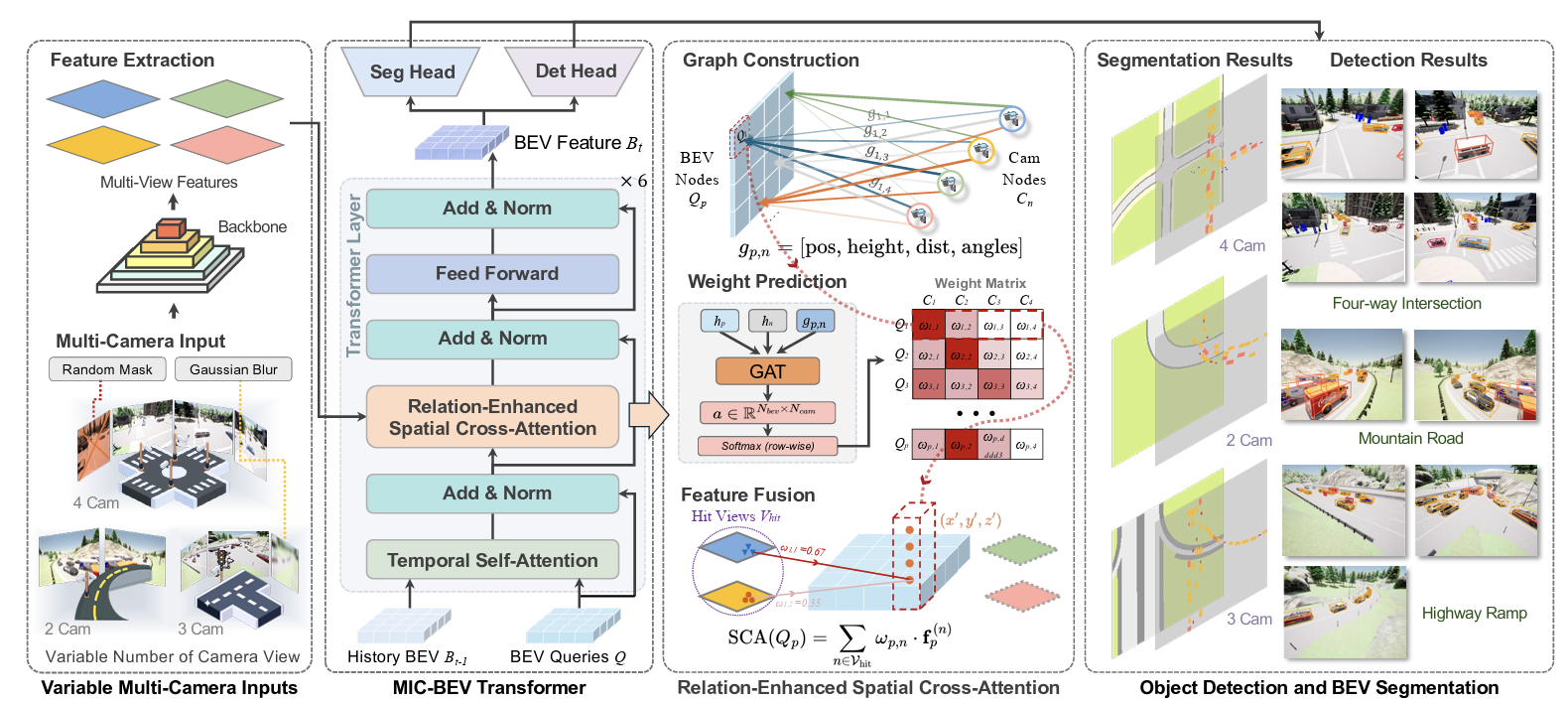 MIC-BEV: Multi-Infrastructure Camera Bird’s-Eye-View Transformer with Relation-Aware Fusion for 3D Object DetectionUnder Review, Best Paper Award (Third Prize)for ICCV 2025DriveX Workshop, 2025Yun Zhang, Zhaoliang Zheng, Johnson Liu, Zhiyu Huang, Zewei Zhou, Zonglin Meng, Tianhui Cai, and Jiaqi Ma
MIC-BEV: Multi-Infrastructure Camera Bird’s-Eye-View Transformer with Relation-Aware Fusion for 3D Object DetectionUnder Review, Best Paper Award (Third Prize)for ICCV 2025DriveX Workshop, 2025Yun Zhang, Zhaoliang Zheng, Johnson Liu, Zhiyu Huang, Zewei Zhou, Zonglin Meng, Tianhui Cai, and Jiaqi Ma -
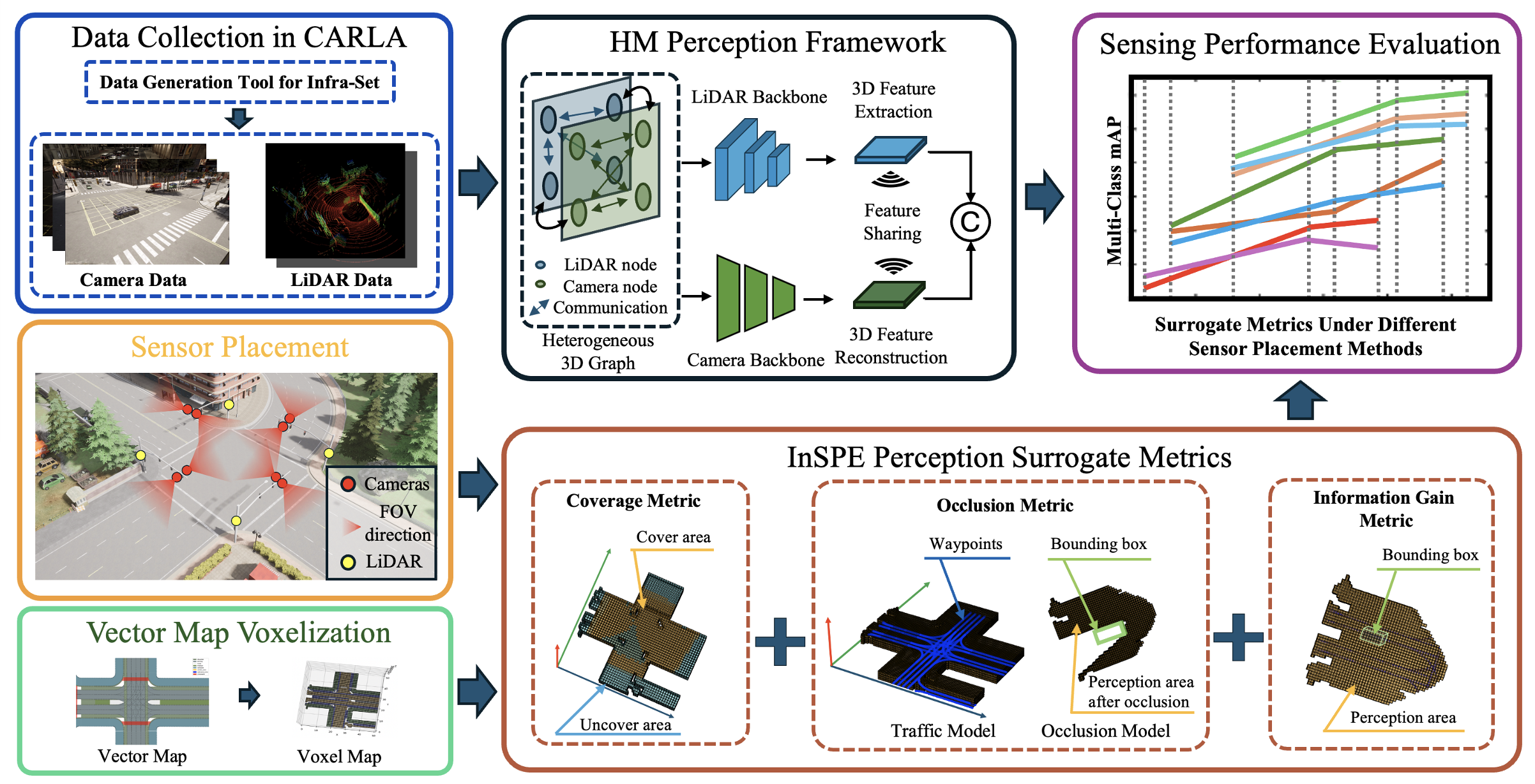 InSPE: Rapid Evaluation of Heterogeneous Multi-Modal Infrastructure Sensor PlacementUnder Review, 2025Zhaoliang Zheng*, Yun Zhang*, Zonglin Meng, Johnson Liu, Xin Xia, Jiaqi Ma
InSPE: Rapid Evaluation of Heterogeneous Multi-Modal Infrastructure Sensor PlacementUnder Review, 2025Zhaoliang Zheng*, Yun Zhang*, Zonglin Meng, Johnson Liu, Xin Xia, Jiaqi Ma -
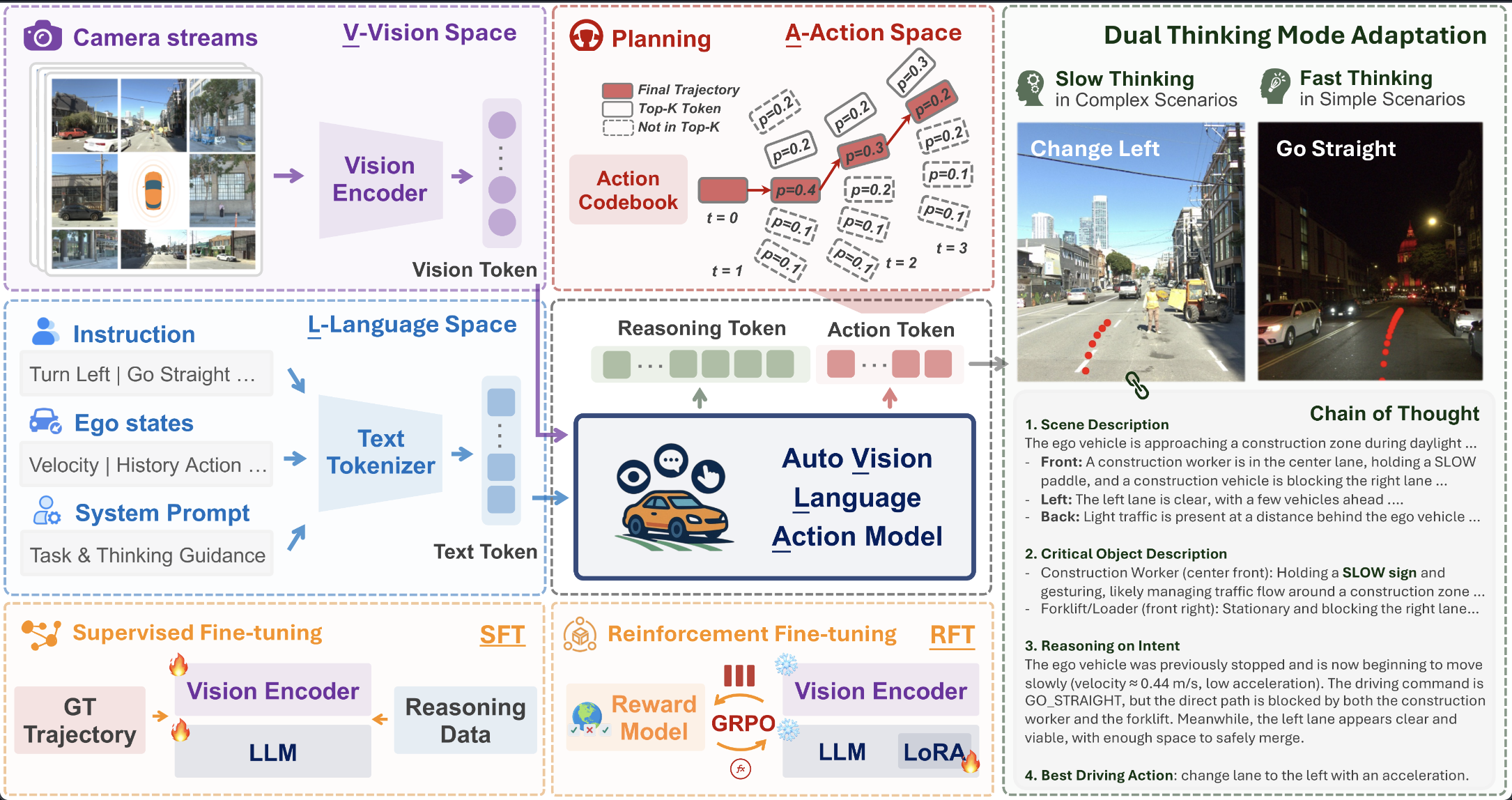 AutoVLA: Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-TuningNeural Information Processing Systems (NeurIPS), 2025Zhiyu Huang, Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Jiaqi Ma
AutoVLA: Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-TuningNeural Information Processing Systems (NeurIPS), 2025Zhiyu Huang, Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Jiaqi Ma



